VAGEN
Reinforcing World Model Reasoning for Multi-Turn VLM Agents
Animated Case Studies





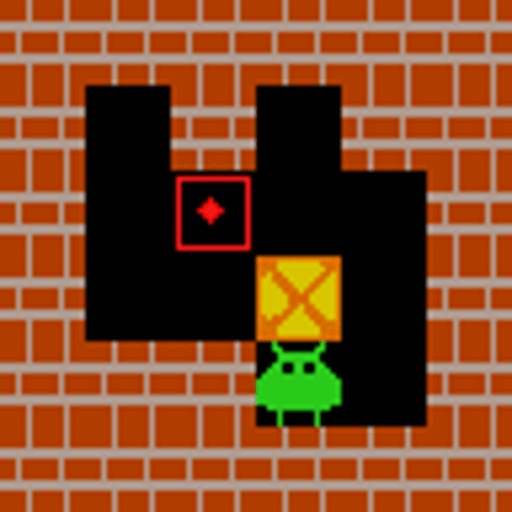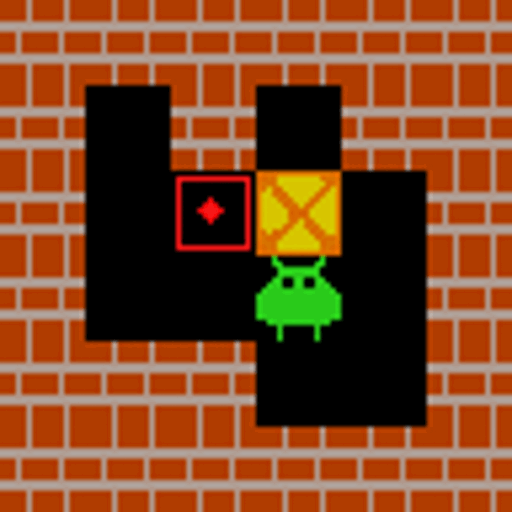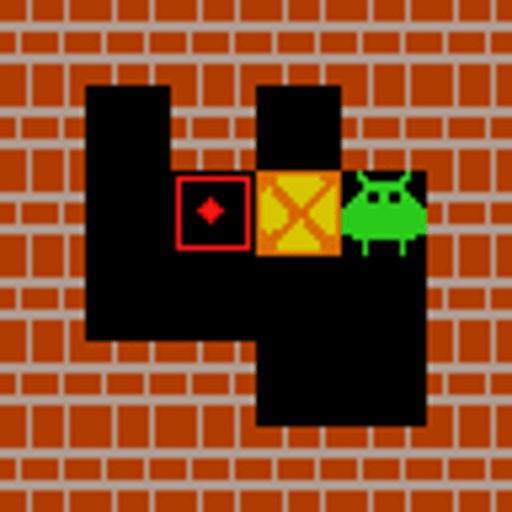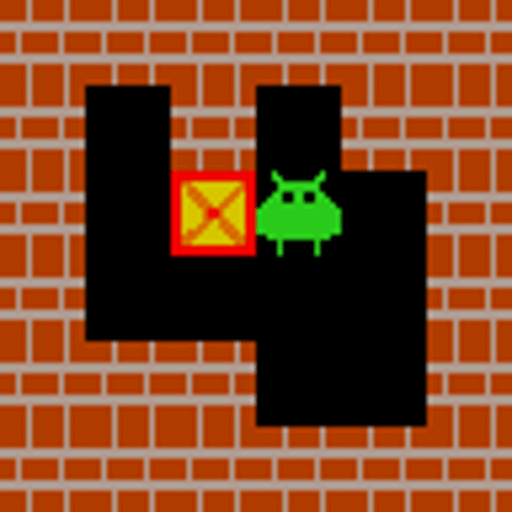




What is VAGEN? World Models + Reinforcement Learning for VLM Agents
VAGEN is a reinforcement learning (RL) framework that trains multi-turn VLM agents (vision-language model agents) to build an internal world model through explicit visual state reasoning. Instead of rewarding only task success, VAGEN reinforces the agent's world model reasoning itself: at every turn, the agent estimates the current visual state (StateEstimation, "what is the current state?") and predicts the next state (TransitionModeling, "what comes next?") inside its chain of thought.
Combining world models with reinforcement learning turns a small open model into a strong visual agent: a 3B-parameter VLM trained with VAGEN reaches an average score of 0.82 across five visual agent benchmarks (Sokoban, FrozenLake, Navigation, PrimitiveSkill manipulation, and SVG generation), a 3× improvement over its untrained counterpart (0.21), outperforming proprietary reasoning models such as GPT-5 (0.75), Gemini 2.5 Pro (0.67), and Claude 4.5 (0.62).
Unlike RL frameworks designed for text-only LLM agents (such as RAGEN) or single-turn visual reasoning (such as VLM-R1), VAGEN targets RL training of VLM agents in multi-turn, partially observable environments (POMDPs), where world modeling, not scale, is what closes the gap. VAGEN was accepted to NeurIPS 2025.
For world model reasoning in spatial view planning, see our related project ViewAgent (Planning with the Views): where VAGEN rewards a VLM agent's internal world model through RL, ViewAgent distills an external, empirical world model of view transitions, built from the agent's own exploration, back into the agent.
Method
Problem Formulation: VLM Agent Training under POMDP
We frame multi-turn VLM agentic tasks as a Partially Observable Markov Decision Process (POMDP), represented by the tuple \((S, O, \phi, A, p, r, \gamma)\), where \(S\) denotes the set of environment states, and \(O\) is the space of observations perceived by the agent.
Each observation \(o_t \in O\) is a partial view of the environment state \(s_t \in S\), given by the observation function \(\phi\). The agent's objective is to learn a policy \(\pi_\theta\) that maximizes the expected cumulative discounted return \[\max_\theta \, E_{\pi_\theta, p} \left[ \sum_{t=1}^{T} \gamma^{t-1} r_t \right]\].
In our setting, the policy \(\pi_\theta\) is parameterized by a VLM that takes in visual images with their prompts as observations, and outputs language token sequences as actions.
Multi-Turn Reinforcement Learning with Visual State Reasoning
Our training algorithm optimizes multi-turn interactions to better address the demands of agentic tasks, with specifications to VLMs in multi-turn, trajectory-based optimization setting.
Trajectory Rollout with Visual State Reasoning
Each trajectory begins with an initial observation \(o_0\) provided by the environment. The agent generates a structured output \(a_t = \langle z_t, \bar{a}_t \rangle\), where \(z_t\) represents reasoning tokens and \(\bar{a}_t\) represents executable actions.
Visual State Reasoning Strategies:
NoThink: We train the VLM agent to generate only an executable action \(\bar{a}_t\), and the output action token \(a_t\) is <answer> \(\bar{a}_t\) </answer>.
<answer>...</answer> Learning: \(z_t = \emptyset\)
FreeThink: We train the VLM agent to produce any form of natural language reasoning, allowing visual state reasoning to emerge without a predefined structure. The agent generates action tokens as <think> \(z_t\) </think> <answer> \(\bar{a}_t\) </answer>.
<think>...</think><answer>...</answer> Learning: \(z_t \neq \emptyset\), and \(z_t\) is natural language tokens.
Grounding: Explicit current state description
<think><observation>...</observation>...</think><answer>...</answer> Learning: \(z_t = \langle \hat{s}_t, a^b_t \rangle\), learning to approximate \(\hat{s}_t \rightarrow s_t\)
WorldModeling: Explicit future state prediction
<think>...<prediction>...</prediction></think><answer>...</answer> Learning: \(z_t = \langle a^b_t, \hat{s}_{t+1} \rangle\), learning to approximate \(\hat{s}_{t+1} \rightarrow s_{t+1}\)
WorldModeling: Combined current and future state reasoning
<think><observation>...</observation>...<prediction>...</prediction></think><answer>...</answer> Learning: \(z_t = \langle \hat{s}_t, a^b_t, \hat{s}_{t+1} \rangle\), learning to approximate \(\hat{s}_t \rightarrow s_t, \hat{s}_{t+1} \rightarrow s_{t+1}\)
Advantage Estimation with Masked GAE
We use a modified form of Generalized Advantage Estimation (GAE) that applies masking to exclude tokens generated by the environment (i.e., non-action tokens) from advantage estimation and loss computation. This ensures that only relevant tokens contribute to the learning signal.
def compute_gae_advantage_return_with_loss_mask(token_level_rewards: torch.Tensor, values: torch.Tensor,
loss_mask: torch.Tensor, gamma: float, lam: float):
"""Modified GAE calculation that handle multi-turn with loss mask
Here we should also ensure that the trajectory score is given at the last valid token instead of last token
Seems it's true in reward manager
Args:
token_level_rewards: `(torch.Tensor)`
shape: (bs, response_length)
values: `(torch.Tensor)`
shape: (bs, response_length)
loss_mask: `(torch.Tensor)`
shape: (bs, response_length). 1 for llm_raw_response, 0 for environment info and paddings
gamma: `(float)`
discounted factor used in RL
lam: `(float)`
lambda value when computing Generalized Advantage Estimation
Returns:
advantages: `(torch.Tensor)`
shape: (bs, response_length)
Returns: `(torch.Tensor)`
shape: (bs, response_length)
"""
with torch.no_grad():
batch_size, gen_len = token_level_rewards.shape
advantages = torch.zeros_like(token_level_rewards)
returns = torch.zeros_like(token_level_rewards)
for b in range(batch_size):
lastgaelam = 0.0
# Find the valid token positions (where loss_mask is 1)
valid_positions = loss_mask[b].nonzero(as_tuple=True)[0]
if len(valid_positions) == 0:
continue
for i in range(len(valid_positions) - 1, -1, -1):
curr_pos = valid_positions[i]
# Get the next value
if i < len(valid_positions) - 1:
# Next valid position
next_pos = valid_positions[i + 1]
nextvalue = values[b, next_pos]
else:
# Last valid position
nextvalue = 0.0
# Calculate delta using the next valid token
delta = token_level_rewards[b, curr_pos] + gamma * nextvalue - values[b, curr_pos]
# Update advantage estimate
lastgaelam = delta + gamma * lam * lastgaelam
advantages[b, curr_pos] = lastgaelam
# Calculate returns for valid positions
for i, pos in enumerate(valid_positions):
returns[b, pos] = advantages[b, pos] + values[b, pos]
advantages = verl_F.masked_whiten(advantages, loss_mask)
return advantages, returns
Policy Update with PPO
We update the actor and critic using the following formulas:
where \(M_i^{loss}\) masks non-action tokens. The trajectory collection, advantage estimation, and policy update iterate until convergence.
Boost #1: WorldModeling Reward
We use LLM-as-Judge to reward the agent when its predicted or observed visual state matches the ground truth.
Boost #2: Bi-Level GAE
To address the limitation of only providing trajectory-level feedback, we propose Bi-Level GAE, which delivers fine-grained turn-level reward signals. This approach assigns rewards at the end of each action and introduces two discount factors: one for tokens within a turn, and one for transitions across turns.
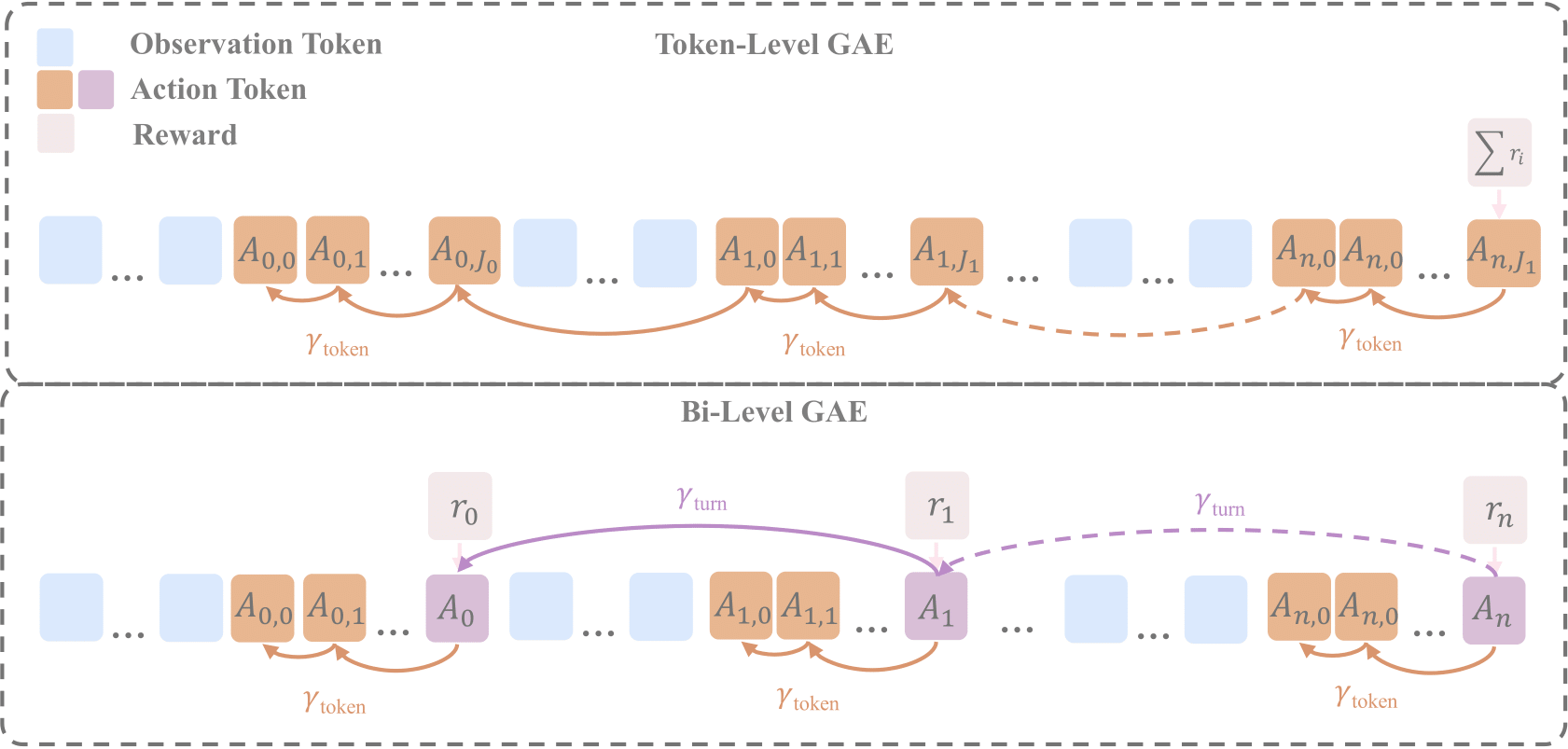
Bi-Level GAE framework illustration.
def compute_bi_level_gae_advantage_return(
token_level_rewards: torch.Tensor,
reward_mask: torch.Tensor,
values: torch.Tensor,
loss_mask: torch.Tensor,
gamma: float,
lam: float,
high_level_gamma: float
):
"""Modified GAE calculation that compute two level of advantage and return:
high level: per-turn wise
low level: token wise
there're two level of MDP, where high level is the agentic MDP and low level is the token MDP
Args:
token_level_rewards: `(torch.Tensor)` (multi-turn reward, per turn reward is given at eos token for each response token sequence)
shape: (bs, response_length)
reward_mask: `(torch.Tensor)`
shape: (bs, response_length). 1 for reward position (end of each llm response)
values: `(torch.Tensor)`
shape: (bs, response_length)
loss_mask: `(torch.Tensor)`
shape: (bs, response_length). 1 for llm_raw_response, 0 for environment info and paddings
gamma: `(float)`
discounted factor used in RL for token rewards
high_level_gamma: `(float)`
discounted factor used in RL for per-turn reward
lam: `(float)`
lambda value when computing Generalized Advantage Estimation
Returns:
advantages: `(torch.Tensor)`
shape: (bs, response_length)
Returns: `(torch.Tensor)`
shape: (bs, response_length)
"""
with torch.no_grad():
batch_size, gen_len = token_level_rewards.shape
advantages = torch.zeros_like(token_level_rewards)
returns = torch.zeros_like(token_level_rewards)
updated_reward = token_level_rewards.clone()
for b in range(batch_size):
# First, calculate high level advantage and return for eos token of each turn using high level gamma
eos_positions=reward_mask[b].nonzero(as_tuple=True)[0]
lastgaelam = 0.0
for i in range(len(eos_positions) - 1, -1, -1):
curr_pos = eos_positions[i]
# Get the next value
if i < len(eos_positions) - 1:
# Next valid position
next_pos = eos_positions[i + 1]
nextvalue = values[b, next_pos]
else:
# Last valid position
nextvalue = 0.0
# Calculate delta using the next valid token
delta = updated_reward[b, curr_pos] + high_level_gamma * nextvalue - values[b, curr_pos]
# Update advantage estimate
lastgaelam = delta + high_level_gamma * lam * lastgaelam
advantages[b, curr_pos] = lastgaelam
for i, pos in enumerate(eos_positions):
returns[b, pos] = advantages[b, pos] + values[b, pos]
updated_reward[b, pos] = advantages[b, pos] + values[b, pos]
# Then, calculate low level advantage and return for each token using gamma, assume the reward for the sequence now is the return at eos token
lastgaelam = 0.0
valid_positions = loss_mask[b].nonzero(as_tuple=True)[0]
for i in range(len(valid_positions) - 1, -1, -1):
curr_pos = valid_positions[i]
if curr_pos not in eos_positions:
# Next valid position
next_pos = valid_positions[i + 1]
nextvalue = values[b, next_pos]
else:
# Last valid position
nextvalue = 0.0
lastgaelam = 0.0
delta = updated_reward[b, curr_pos] + gamma * nextvalue - values[b, curr_pos]
lastgaelam = delta + gamma * lam * lastgaelam
advantages[b, curr_pos] = lastgaelam
returns[b, curr_pos] = lastgaelam + values[b, curr_pos]
advantages = verl_F.masked_whiten(advantages, loss_mask)
return advantages, returns
Results
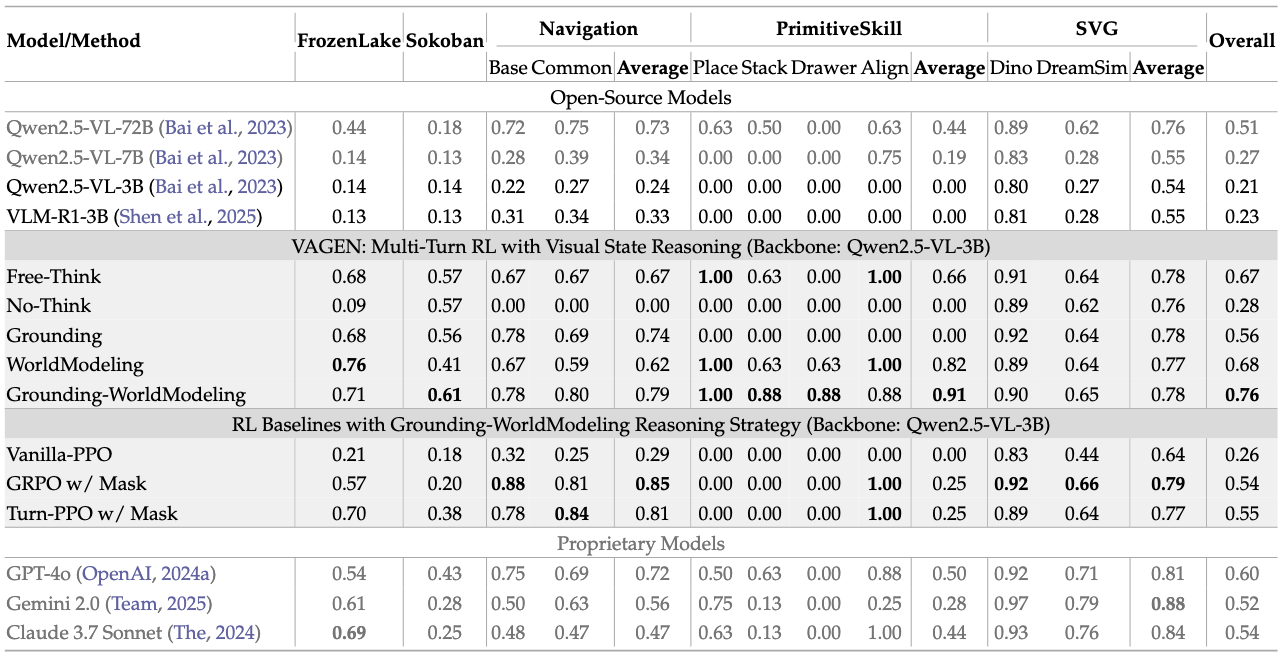
Explicitly visual states reasoning is crucial for VLM agents.
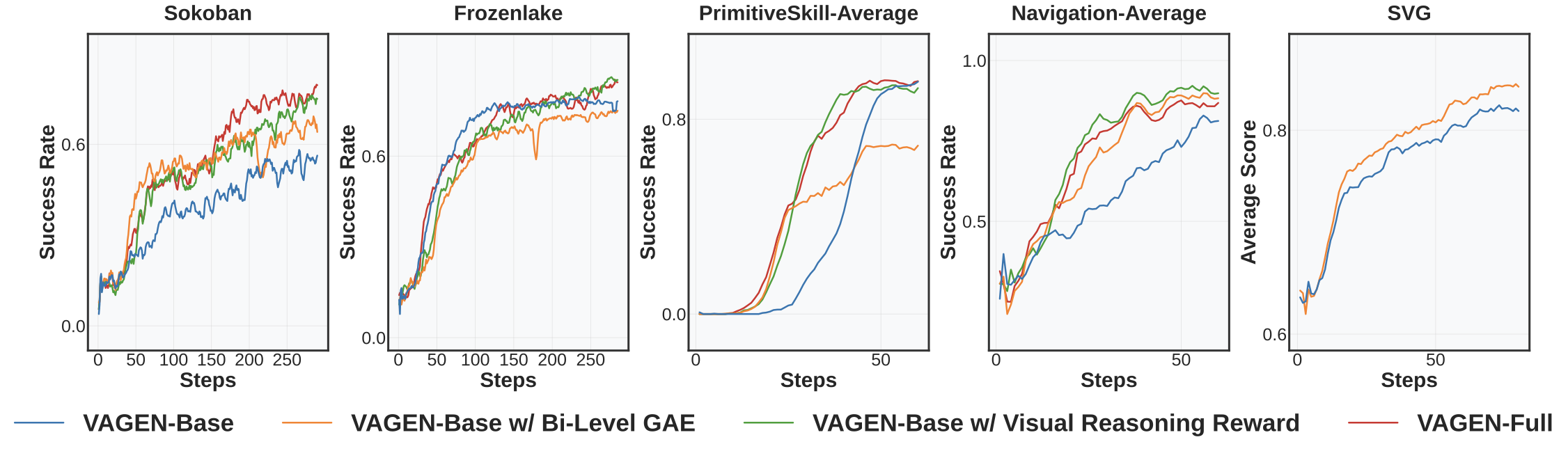
- Bi-Level GAE alone brings notable but unstable improvements, being sensitive to reward sparsity and less stable in sparse environments.
- The WorldModeling Reward alone consistently boosts performance by providing essential visual learning signals, but is limited by coarse credit assignment.
- VAGEN-Full is the most robust and achieves strong, stable results across all tasks.
Cases
Case : Enhanced Visual State Reasoning with VAGEN-Full

Summary of Findings
Finding 1: Explicit Visual State Reasoning is Crucial for Multi-Turn VLM Agents
Vanilla VLMs struggle with multi-turn agentic tasks requiring visual state understanding. Integrating explicit visual state reasoning steps—specifically StateEstimation and TransitionModeling—into the VLM's thinking process during RL training significantly enhances task performance. The combined WorldModeling strategy, in particular, demonstrates strong and stable performance, enabling a trained open-source VLM to outperform its un-trained counterpart and even surpass benchmarked proprietary models.
Finding 2: Optimal Visual State Representation is Task-Dependent
The choice of representation for visual states during explicit reasoning significantly impacts performance:
- Natural Language: Performs consistently well, especially when structured information must be inferred from raw visual input.
- Structured Formats: Excel in manipulation-heavy tasks (e.g., PrimitiveSkill) where object-centric state abstractions are readily available.
- Symbolic Representations: Proved less effective due to the model's limited prior interpretability from visual input.
Finding 3: Visual Reasoning RL with Targeted Rewards and Bi-Level GAE Enhances Reasoning Quality and Task Success
To specifically improve visual state reasoning, Visual Reasoning RL incorporates:
- Turn-level WorldModeling Reward: An LLM-as-a-Judge assesses the accuracy of the VLM's explicit state descriptions and predictions, effectively supervising reasoning.
- Bi-Level General Advantage Estimation (GAE): Estimates advantages at both turn and token levels, providing finer-grained reward signals and improving credit assignment.
This approach consistently outperforms Base RL, leading to improved reasoning quality, higher task success rates, and better generalization.
Finding 4: Emergent Reasoning Patterns and Challenges
Beyond quantitative measurements, we qualitatively analyzed how agents learn to reason:
- Reasoning Stability Varies by Task: While reasoning in tasks like Navigation and PrimitiveSkill (and often Sokoban) appears relatively normal and beneficial with explicit rewards, tasks like FrozenLake show more erratic reasoning patterns, potentially correlating with its lower performance and the difficulty of its visual state reasoning.
- Potential for Reward Hacking: Instances of "reward hacking" were observed, particularly with certain reward configurations. Agents might learn to generate reasoning-like text that satisfies the reward mechanism without genuinely reflecting deep understanding or accurate future prediction.
- Bi-Level GAE as a Double-Edged Sword: While Bi-Level GAE can improve credit assignment, its interaction with WorldModeling Rewards might sometimes allow for more "divergent" or less grounded thinking if the reasoning reward itself can be easily hacked.
- Convergence to Standardized Phrasing: Agents across different environments tend to converge towards using a more uniform, templated sentence structure for their reasoning and actions over prolonged training, primarily varying only the directional or specific action tokens.
- Rule-Based Filtering as a Potential Mitigation: For simpler forms of reward hacking where reasoning outputs fail basic semantic checks, simple rule-based filtering before reward assignment could be a pragmatic interim solution.
These observations underscore that while explicit reasoning and rewards are beneficial, the design of these rewards must be robust against exploitation, and continuous monitoring of reasoning quality is essential.